Deeplearning : Facebook passe DLRM en open source
Écrit par Ariane Beky
Accéder à l'article original• Analyse de l'article
Cet article nous parle de Facebook et de son algorithme de recommendation "DLRM", utilisant la puissance du deep learning pour recommander un contenu plutôt qu'un notre sur Facebook. DLRM a donc été rendu public sur GitHub, une platforme de partage de code très connue au sein de la communanuté open source.
Cet algorithme, codé en Python et utilisant la librairie PyTorch (librairie de deeplearning très utilisée, car très puissante) ainsi que le framework Caffe2 (une sorte de librairie spécalisée dans le machine learning) nous montre donc plus clairement (d'une certaine manière) comment l'algorithme détermine la possibilité que la personne clique la plutôt qu'autre part.
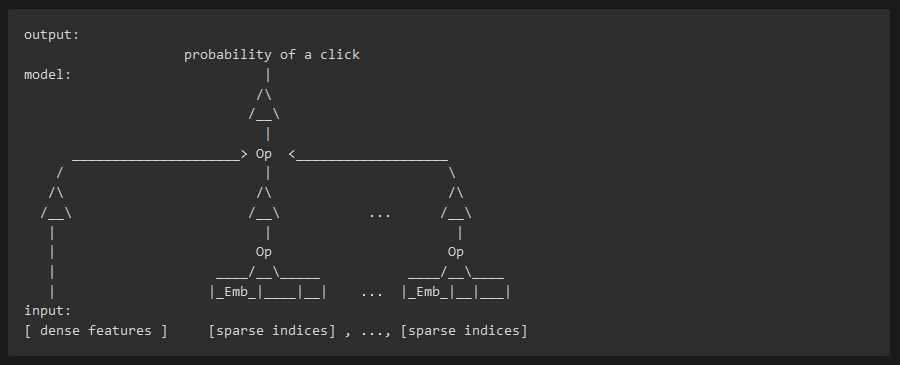
Cette explication "simplifiée" nous montre la versatilité de cet algorithme; plusieurs parametres sont donnés a l'algorithme, qui va tous les prendre en compte affin d'en sortir le meilleur choix possible. Ici, ce choix est la "possibility of a click", littéralement la "possibilité d'un clic".
L'article parle évidemment de l'utilisation de cette algorithme, en citant les GAFAM (Google / Apple / Facebook / Amazon / Microsoft). On peut donc remarquer que Facebook est la première entreprise des GAFAM a rendre disponible ses algorithmes publiquement, qui avais déjà auparavant rendu publique la librairie "PyRobot", un framework touchant a l'IA et comme son nom l'indique, la robotique.
• Points de vues
L'auteur de cet article ne fait que reporter les faits; néanmoins on peut constater un entousiasme a l'idée de cet algorithme open source, notamment avec la dernière phrase : Les modèles en question sont, heureusement, perfectibles. qui laisse entendre que le futur de cette technologie est prometteur.
Pour moi, cette technologie a beaucoup de potentiel, mais attention aux dérives, l'open source est bien mais accessible a tous; pour le meilleur et pour le pire.